Project 1 - Detecting Lane
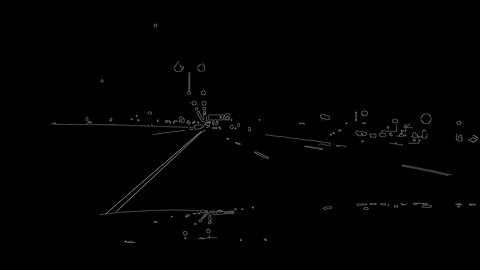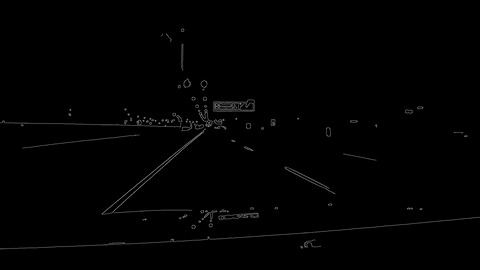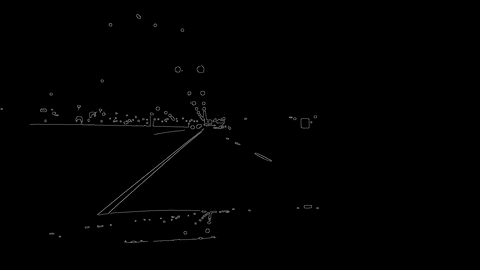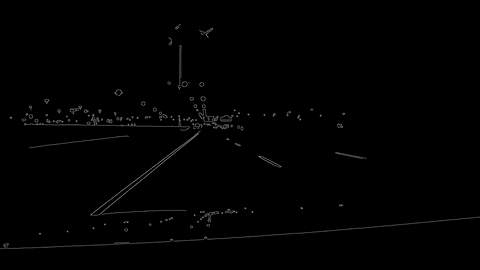
The first project for the Udacity Self-Driving Car Nanodegree was to create a software pipeline capable of detecting the lane lines in video feed. The project was done using Python with the bulk of work being performed using the OpenCV library. The video to the side shows the software pipeline I developed in action using video footage I took myself.

Guess Probability: 100.0 % - Road work
Below you can see the results of the neural network when given a number of different images. For each image the neural network outputs a guess and the % of confidence it has for that guess. Of the examples below, the neural network is least confident about the slippery road sign. However the image is so dark that in order for me to tell what sign it is I had to increase the brightness on the image.
To see the full project code visit my Github page.
Project 2 - Traffic sign classifier
For project 2 I created a traffic sign classifier using a convolution neural network that achieved a 94.6% test accuracy on the German Traffic Sign Dataset. The dataset contains 39,209 training images and 12,630 test images. The training images and test images are kept separate so that the neural networks performance is evaluated on images it didn't see during training.
If you had to teach an alien on how to distinguish between different traffic signs there are essentially two ways you could go about it. The first way would be to very accurately describe the features of all the different signs. This could get difficult fast as you can't just describe the road work sign as a person shoveling dirt (since the alien won't know what a person, dirt, or shoveling look like). The second way to go about it would be to give the alien a whole bunch of example images of traffic signs with an accompanying label for each one. The alien would then figure out on its own what features of a traffic sign make it fall into each category. This second way is essentially how neural networks operate. You train it on the training traffic sign images (which it uses to figure out what features make a traffic sign fall into each category). Just as if you were to give the alien a quiz to see how well its learning, the test images of the data set are used to test the performance of the neural network.

Guess Probability: 100.0 % - No passing

Guess Probability: 59.7 % - Slippery road

Guess Probability: 99.9% - Speed limit (100km/h)

Guess: 100.0 % - No passing vehicles over 3.5 tons

Brighter slippery road image (not used by classifier)

Brighter speed limit image (not used by classifier)
This model isn't the best one that I trained and I didn't end up submitting it for my project (mainly because it doesn't do the first corner well) but I'm showing it here because it handles the two tight turns after the bridge so well. I also have the throttle set to a much faster speed than was required by the project.
Project 3 - Behavioral cloning
Project 3 of the Nanodegree was to build and train a deep neural network to drive a car around a race track. A Unity simulator imitates a camera on the front of a car taking pictures at a rate of 10 Hz. These pictures are then sent to the neural network. An example of one of these pictures can be seen to the left. The neural network would then send a steering wheel angle back to the simulator based on the picture it received.
The neural network is trying to act just like a person. By looking at the road in front of it (through images taken by the camera on the car) the neural network decides how far to turn the wheel left or right.

My total training data set contained just over 11,000 images.
To gather training data for the neural network I drove around the track myself and recorded the cameras output as well as the steering wheel angle I used. Using this data to train on, the neural network would learn what steering wheel angle is required when it sees certain features in the images (such being close to the curb). However, it wasn’t enough to just drive multiple laps on the center line of the race track as the neural network had to learn what to do when it inevitably left the center of the track.

The model response is in black and the test data (me driving a lap) is in red. Notice that the model follows the data very accurately but doesn't catch the noise (which was me intentionally doing a quick left then right of the steering wheel) located at data point 370. The Y axis is the steering angle and the x axis is the frame number.
In order to teach the neural network how to get back to the center of the track I would stop recording data, place the car on the edge of the track, and then turn on data recording while driving from the edge back to the center. With both the driving down the track normally data and the driving from the edge back to the middle data, I was essentially teaching the neural network how to execute each corner while also teaching it an aversion for driving near the edges.
I found that a 5 layer convolution network followed by a 5 layer dense network was sufficient to fit the training data. Below is a snippet of the Keras model code. When training the model I used the Adam optimizer with a mean squared error loss function. After 30 training epochs I dropped the learning rate by a factor of two and trained for another 15 epochs. To the left is a graph of the trained model performing a lap on the test data (new data that it wasn't trained on).
The video at the top shows the final product of the neural network successfully completing a lap around the racetrack. At the end of the video I shut off the network to prove that it was actually doing something.
To see the full project code visit my Github page.
The description of the three mini videos are as follows:
- Top left - perspective transform - allows birds eye view of the road.
- Top Right - gradient and color threshold - allows filtering of pixels that are most likely part of lane line as in project 1.
- Bottom right - sliding window - the windows attempt to follow the lane lines. Only the pixels within each lanes windows are used in the radius of curvature calculation. This allows for considerable reduction in noise.
project 4 - advanced lane lines
For project 4 the goal was to used more advanced techniques to than project 1 to extract the lane line information from a camera feed. In addition to the lane line information being displayed visually, the distance of the car from the center line and the radius of curvature of the corner will also be estimated.
Both this project and project 1 used image analysis techniques such as gradients or color thresholding in order to identify the pixels that make up part of the lane line. Whats different about this project is the use of a perspective transform (to have a birds eye view of the lane, easier to calculate things from that) and a sliding window that tracks the lane line from frame to frame in order to remove any excess noise from its radius of curvature calculation. Both the birds eye view of the lane and the sliding window can be seen in the video to the left.
Below is a picture of a video frame that has gone through the gradient and color threshold and then a perspective transform.
To see the full project code visit my Github page.

Project 5 - Vehicle Detection
The goal of project 5 was to identify and track vehicles from a video feed. A histogram of oriented gradients is used to extract features from an image so that it can be used in a support vector classifier, which is a form a machine learning that is lighter and faster than neural networks. An image with the histogram of oriented gradient features extracted can be seen below. The classifier is trained on images from the GTI vehicle image database and the KITTI vision benchmark suite.

A sliding window search is used to feed small windows of the video feed one by one into the classifier where they will be classified as either an image belonging to a car or not. Three window sizes are used to identify cars far, medium, and close distance from the camera. Each window size spans the width of the image and uses overlap to provide more possibilities to outline a car so that it can be detected by the classifier.

The medium sliding window size (shown) is used to detect cars at medium distance from the camera. The right figure just shows each window stacked 2 high and 12 wide. The left figure shows 50% overlap between all the windows.
In order to increase detection chances once a car has been detected, a focused window search is added to the sliding window which adds more windows to a location that previously had a high confidence detection of a car.

A car is considered detected when 3 or more overlapping windows are classified as belonging to a car by the support vector classifier. This also helps reduce the number of false positives (the classifier identifying a window as containing a car when it doesn't) reported. Since the support vector classifier has a 97% accuracy and there are hundreds of sliding windows, there are bound to be a few false positives in each frame.

In the end my final submission still had a few false positives showing up but I was able to track both the cars for the entire duration they were within view of the camera.
By passing this project I've completed term 1 of the nanodegree, two more terms to go!